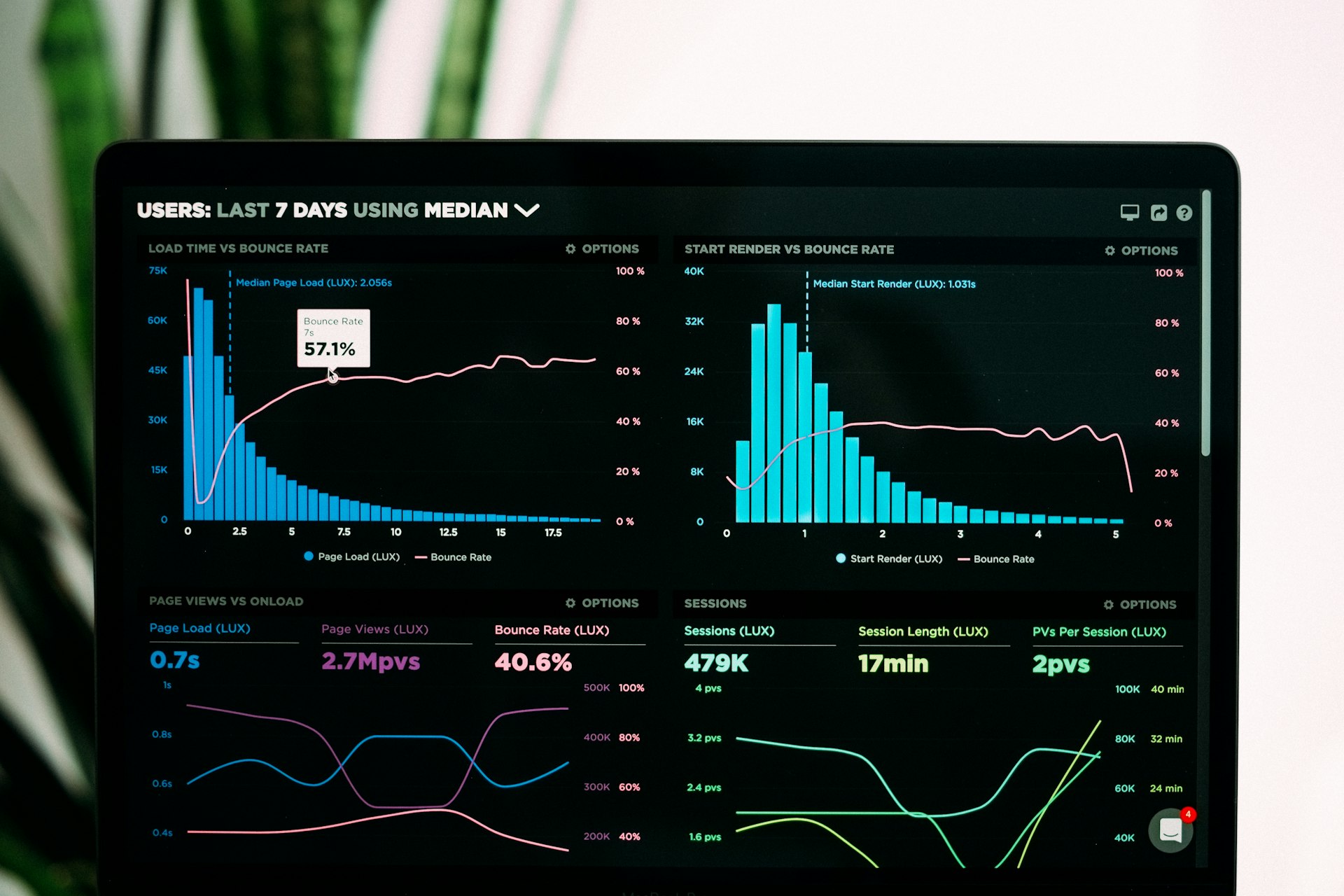
Большинство IT-систем не «падают внезапно». Они ломаются постепенно, просто бизнес узнаёт об этом слишком поздно — от клиента, партнёра или бухгалтера, заметившего «странности» в отчёте.
Когда мы начинаем разбор таких проектов, почти всегда обнаруживается одно и то же: система работает без полноценного мониторинга и логирования. Не «совсем без», а на уровне «есть какие-то логи, есть какой-то Grafana, кто-то иногда смотрит». В критичный момент это эквивалентно отсутствию.
Пока всё спокойно — это кажется не проблемой. Но как только появляется нагрузка, рост или нестандартный сценарий, система превращается в чёрный ящик. Команда не понимает, что внутри происходит, не может воспроизвести ошибку, не может предсказать проблему до того, как клиент о ней напишет.
В этой статье — разбор того, почему отсутствие наблюдаемости — это не технический нюанс, а гарантированная причина будущих сбоев. И как выглядит минимально достаточный уровень мониторинга и логирования, который имеет смысл закладывать в любую систему, от MVP до зрелого корпоративного продукта.
Контекст: CI/CD и DevOps для бизнеса: зачем это нужно, если «и так работает» — зачем DevOps бизнесу; High-load системы в России: как готовиться к нагрузке до того, как она случилась — подготовка к нагрузке.
01 · Что бизнес обычно понимает под «у нас всё работает»
Когда руководитель говорит «у нас система работает стабильно», в большинстве случаев это означает примерно следующее:
- Ошибки иногда появляются, но «само проходит». Кто-то жалуется на форму, через 5 минут «уже работает».
- Если что-то сломалось — смотрим логи вручную. SSH на сервер,
tail -f, grep. - Уведомления приходят, когда уже есть жалобы. Клиент написал в поддержку — поддержка передала разработчикам.
- Причины инцидентов ищут постфактум. Через неделю после инцидента кто-то ещё пытается понять, что произошло. Обычно не находит.
- Повторяющиеся проблемы считают «особенностью системы». «У нас иногда зависает выгрузка отчётов — это известная история».
- Метрики смотрят раз в месяц на встрече с инвесторами. В операционном режиме их никто не открывает.
- «Дашборд работает или нет?» — никто не знает. Где он, кто его настраивал, актуальны ли цифры — непонятно.
Это не стабильность. Это отсутствие видимости. Система выглядит «работающей», потому что её внутреннюю работу никто не наблюдает. Если бы наблюдали — увидели бы накапливающиеся проблемы заранее.
Граница между «работает» и «не работает» — это граница доходящих до владельца жалоб. Всё, что не дошло — невидимо: потерянные заявки, медленные операции, ошибки фоновых задач, дрейф данных, постепенный рост latency. Бизнес узнаёт о проблеме не когда она появилась, а когда стала массовой.
02 · Почему системы без мониторинга ломаются снова и снова
Есть три структурные причины, по которым отсутствие наблюдаемости гарантирует повторяющиеся сбои.
Причина 1: проблемы не видны заранее.
Без мониторинга бизнес узнаёт о проблемах слишком поздно, без контекста и без понимания масштаба. Вместо сигнала «нагрузка растёт, мы близки к пределу» команда получает сигнал «сайт не работает». Между этими двумя сигналами обычно проходит несколько часов или дней — времени, которого было бы достаточно для проактивных действий.
Реальные примеры из практики:
- Очередь обработки заявок медленно растёт, через 3 дня переполняется и теряет события. Без мониторинга очереди — никто не заметил, пока пользователи не начали жаловаться.
- БД использует 80% диска. На 95% начинают появляться ошибки записи. На 100% — продакшен останавливается. Без мониторинга диска — узнаёт от клиента.
- Внешний API партнёра вернул 10% ошибок. Через неделю — 30%. Через месяц — 60%. Без мониторинга интеграций — узнают по падению выручки.
- Время отклика медленно растёт от 200мс до 2 секунд за квартал. Без мониторинга latency — узнают, когда пользователи начнут отписываться.
Мониторинг нужен не для красивых графиков. Он нужен, чтобы предупреждать, а не реагировать. Это разница между профилактикой и скорой помощью.
Причина 2: ошибки невозможно воспроизвести.
Фраза, которую слышали все команды разработки: «Сейчас уже всё нормально, повторить не можем».
Без структурированного логирования:
- Невозможно понять последовательность событий, приведших к сбою.
- Невозможно увидеть, что именно делал пользователь.
- Невозможно увидеть, какие запросы прошли, какие нет.
- Невозможно доказать причину.
В итоге проблема остаётся, решение — временное (перезапустили сервис, очистили кэш, «само прошло»), сбой повторяется через неделю, через месяц, через квартал. Каждый раз — разбирается заново, каждый раз — никто не понимает причину.
Это особенно опасно в системах с финансовыми операциями. Двойное списание у клиента «один раз», потом «ещё один раз». Без логов невозможно понять, баг это или нет, и нужно ли возвращать деньги.
Причина 3: ответственность размывается.
Когда нет данных, виновником становится «сервер», «внешний сервис», «сеть», «что-то странное». В таких условиях:
- Невозможно определить источник проблемы. Без трейсов и логов отладка — это гадание.
- Сложно принимать архитектурные решения. Что оптимизировать, что переписывать, что масштабировать — без данных это интуиция.
- Ответственность смещается в догадки. «Виновата база, давайте увеличим RAM», «виновата сеть, давайте поднимем таймаут».
Это особенно критично в enterprise-системах с интеграциями. Когда сбой может быть в одном из 10 связанных сервисов, без observability разбор инцидента занимает не часы, а дни. И часто заканчивается «непонятно почему, но больше не повторяется» — с оставшимся риском, что повторится завтра.

03 · Логирование — это не «писать всё подряд»
Частая ошибка — думать, что логирование = много логов. Команда думает «давайте логировать вообще всё, что происходит» и в итоге получает терабайты бесполезных данных.
На практике в логах важны несколько свойств:
Структурированность. Логи в виде JSON, не свободного текста. С полями timestamp, level, service, request_id, user_id, message, extra. Структурированные логи можно индексировать, фильтровать, искать по полям. Свободный текст можно только grep-ать вручную.
Понятные уровни. debug — для разработки. info — нормальные события. warn — что-то странное, но не критичное. error — нужно внимание. fatal — система не может продолжить. Правильное использование уровней позволяет настраивать алерты на error+ и не утопать в шуме.
Связь событий между сервисами. Каждый запрос имеет request_id (или trace_id), который пробрасывается через все сервисы. Когда нужно разобрать инцидент, можно вытащить все логи по этому ID — и увидеть весь путь запроса от пользователя до БД и обратно.
Контекст запроса и пользователя. Логи без контекста бесполезны. ERROR: failed to process — что произошло? Чей запрос? С какими параметрами? Логи с контекстом: ERROR: failed to process order. user_id=12345, order_id=67890, error=insufficient_funds, stack=....
Категории событий. Бизнес-события (order_created, payment_processed) отдельно от технических (db_connection_lost, cache_miss). Это позволяет строить разные дашборды и алерты.
Контроль чувствительной информации. PII (паспорта, телефоны, email) не должны попадать в логи. Это требование 152-ФЗ. Маскирование, фильтры, явные правила в коде.
Хаотичные логи:
- Не помогают при разборе — их слишком много и они без контекста.
- Замедляют разбор —
grepпо терабайту неструктурированного текста. - Создают ложное ощущение контроля — «у нас же логи есть».
- Скрывают важные события в потоке шума.
Подробнее: devops infrastructure.
04 · Мониторинг — это не только «жив ли сервер»
Очень распространённая ситуация в проектах с базовым мониторингом:
- Сервер «зелёный», health-check проходит.
- CPU в норме, память не превышена, диск не заполнен.
- Сетевые подключения работают.
А бизнес-процесс не работает. Заявки не приходят, отчёты не строятся, синхронизация с 1С застряла.
Почему? Потому что мониторят инфраструктуру, но не бизнес-логику. Эти две вещи могут жить параллельно — инфраструктура работает, бизнес-процессы — нет.
Полная картина наблюдаемости включает несколько слоёв:
Слой 1: инфраструктурные метрики. CPU, RAM, диск, сеть, network errors. Это базовая гигиена, без неё нельзя, но этого недостаточно. Зелёные графики инфраструктуры не означают, что продукт работает.
Слой 2: метрики приложения. Latency, error rate, request rate (RED-методология). Для каждого критичного эндпоинта. Это уже ближе к бизнесу — показывает, отвечает ли API, как быстро.
Слой 3: метрики компонентов. Размер очередей, время обработки задач, количество подключений к БД, hit rate кэша. Это метрики того, как система работает внутри.
Слой 4: метрики бизнес-процессов. Количество созданных заявок за час. Время от создания до закрытия. Количество успешных платежей. Количество неуспешных. Это то, что важно бизнесу, и это часто не мониторят.
Слой 5: метрики внешних интеграций. Время отклика партнёрских API, error rate, количество retries. Внешние системы — это типичная точка отказа, которую часто упускают.
Слой 6: пользовательский опыт. Real User Monitoring — что чувствует пользователь. Скорость загрузки страниц, ошибки в браузере, успешность критичных сценариев.
Без мониторинга очередей, внешних интеграций, бизнес-метрик система может быть «жива» технически и «мертва» для бизнеса. И когда мониторят только нижние слои — узнают о проблеме только когда она дошла до клиента.

05 · Почему без наблюдаемости нельзя масштабироваться
При росте системы происходит несколько процессов одновременно:
- Увеличивается количество запросов в единицу времени.
- Растёт сложность сценариев (новые фичи, новые сегменты клиентов).
- Появляется асинхронность (очереди, фоновые задачи).
- Добавляются интеграции (новые партнёры, новые внешние сервисы).
- Увеличивается команда — больше разработчиков работают одновременно.
Без мониторинга и логирования в такой растущей системе:
Невозможно понять, где узкое место. Что именно тормозит — БД, внешний API, очередь, фронтенд? Без метрик это гадание.
Невозможно прогнозировать нагрузку. Тренды роста запросов, размера БД, очередей — это всё нужно для capacity planning. Без данных — невозможно.
Невозможно безопасно оптимизировать. «Давайте перепишем поиск на Elasticsearch» — а помогло? Без метрик до и после — неизвестно.
Невозможно разобрать инцидент. Каждая аварийная ситуация — это часы или дни на «понять, что случилось».
Невозможно принимать архитектурные решения. Выделять модуль в сервис или нет? Делать read-реплики или нет? Без метрик — это интуиция.
В результате масштабирование превращается в:
- Риск. Каждое изменение может что-то сломать, и команда боится экспериментировать.
- Стресс. Команда живёт в режиме «лишь бы не упало».
- Аварийные фиксы. Меняем что-то под давлением инцидента, без понимания причин.
- Потерянное время. Часы разбора инцидентов вместо часов разработки.
Подробнее: High-load системы в России: как готовиться к нагрузке до того, как она случилась и Как запустить MVP, который выдержит рост ×10 — без переписывания архитектуры.
06 · Как отсутствие логирования увеличивает стоимость ошибок
Каждый инцидент без нормальных логов:
- Разбирается дольше. 30 минут вместо 5. Часы вместо минут. Дни вместо часов.
- Требует больше людей. Без логов нужны разработчик, DevOps, DBA, проект-менеджер — все обсуждают, что могло случиться.
- Отвлекает ключевых специалистов. Лучшие инженеры тратят время на «гадание о причине».
- Увеличивает простой. Каждая минута простоя — это потерянная выручка и репутация.
- Снижает уверенность в системе. Если причина неизвестна, как гарантировать, что не повторится?
Финансово это означает:
- Прямые потери. Простой сервиса = недополученная выручка.
- Репутационные риски. Клиент в B2B запомнит, что у вас было 3 крупных инцидента за квартал.
- Снижение доверия клиентов. Особенно корпоративных, которые ожидают SLA.
- Рост операционных расходов. Команда тратит больше времени на эксплуатацию, меньше на развитие.
- Stress-leave и текучка. Команда устаёт от постоянных авралов, лучшие уходят.
- Штрафы и compliance-инциденты. Если в инциденте были задеты ПДн, и нет логов для доказательства реакции — это проблема с регулятором.
Мониторинг и логирование не предотвращают ошибки. Ошибки будут — это нормальная часть жизни любой системы. Но наблюдаемость делает их управляемыми:
- Ошибки видны быстро.
- Причины понятны.
- Реакция предсказуема.
- Восстановление быстрое.
- Уроки извлекаются и закладываются в систему.
Это разница между «всё горит, не понимаем что делать» и «вот эта ошибка, вот причина, вот реакция, через 15 минут восстановим».
07 · Distributed tracing для систем с несколькими сервисами
Когда система состоит из нескольких сервисов (даже модульный монолит с интеграциями — это распределённая система), отдельная важная часть наблюдаемости — это distributed tracing.
Что это: способ проследить путь одного пользовательского запроса через все сервисы и компоненты.
Простой пример. Пользователь нажимает «купить»:
- Frontend отправляет запрос в API.
- API проверяет наличие через WMS-сервис.
- API проверяет цену через pricing-сервис.
- API создаёт заказ в БД.
- API инициирует платёж через payment-провайдера.
- API отправляет событие в очередь.
- Worker берёт событие, обновляет 1С.
- Worker отправляет email-уведомление.
Если этот процесс «иногда падает», без трейсов разобраться невозможно. С трейсами:
- Видим весь путь запроса с timestamp-ами.
- Видим, какой шаг занял больше всего времени.
- Видим, где именно произошла ошибка.
- Видим, какие параметры передавались между сервисами.
Инструменты в российском контексте: Jaeger, Zipkin, OpenTelemetry (стандарт), Yandex Cloud Tracing. Все open-source, все интегрируются с существующими стеками.
Distributed tracing обязателен для систем из 3+ сервисов. Без него отладка распределённой системы — это игра в угадайку.

08 · Почему enterprise-подход начинается с наблюдаемости
Enterprise-архитектура — это не про «сложно». Это про предсказуемость.
В зрелых системах:
- Каждое значимое событие отслеживается.
- Каждое отклонение видно.
- Каждое решение опирается на данные, не интуицию.
- Каждый инцидент имеет post-mortem с конкретными выводами.
Без наблюдаемости:
- Архитектура неуправляема. Невозможно понять, как система реально работает.
- Автоматизация неэффективна. CI/CD без метрик после деплоя — это «выкатили и надеемся».
- DevOps не работает. Без observability DevOps превращается в «деплой через скрипт».
- High-load опасен. Невозможно предсказать поведение под нагрузкой.
- Compliance невозможен. Регулятор требует доказательств, аудит-trail, контроля.
- Масштабирование команды затруднено. Новые разработчики не могут разобраться в системе.
В корпоративном продукте 2026 года наблюдаемость — это не отдельная функция, это часть архитектуры. Каждый компонент при создании сразу имеет логи, метрики, трейсы. Каждый алерт документирован. Каждый дашборд имеет владельца.
Это не «дорого». Это операционная гигиена, без которой устойчивая работа продукта невозможна.
Узнайте о DevOps и инфраструктуре: devops infrastructure.
09 · Самая частая ошибка компаний
Ошибка звучит так: «Добавим мониторинг, когда будут проблемы».
Но мониторинг и логирование:
- Не внедряются мгновенно. Это 4–12 недель работы для среднего продукта.
- Требуют понимания архитектуры. Что важно мониторить, на что ставить алерты, что игнорировать.
- Нуждаются в настройке и культуре использования. Дашборды без открывающих их людей — это бесполезные графики.
- Требуют ретроспективной работы с данными. Чтобы знать «что норма», нужно собирать данные несколько недель.
Когда проблемы уже есть — времени на это нет. Команда занята тушением пожаров, а не настройкой Prometheus и Loki. И каждый день без наблюдаемости — это новые недопонимания и новые инциденты.
Гораздо дешевле:
- Заложить наблюдаемость заранее — на стадии MVP или ранней разработки.
- Начать с базового уровня — не нужно полного стека от первого дня.
- Развивать по мере роста — добавлять метрики и алерты по мере появления новых компонентов.
Это в 5–10 раз дешевле, чем внедрять с нуля под давлением инцидентов.
10 · Как выглядит минимально достаточная наблюдаемость
Важно: не нужен «космический» стек. Не нужно с первого дня Prometheus + Loki + Tempo + Jaeger + Grafana + Alertmanager + PagerDuty + Datadog параллельно. Это пугает собственников и превращает внедрение в большой проект.
Для большинства бизнес-систем достаточно:
Логи:
- Структурированные JSON-логи в централизованном хранилище.
- Loki / Elastic / Datadog / Yandex Cloud Logging — на выбор.
- С полями
request_id,user_id,service,level. - С маскированием PII.
- Retention минимум 30 дней.
Метрики приложения:
- RED-метрики (Rate, Errors, Duration) для критичных эндпоинтов.
- USE-метрики (Utilization, Saturation, Errors) для ресурсов.
- Базовые бизнес-метрики (конверсии, регистрации, заказы).
- Prometheus + Grafana или эквивалент.
Алерты:
- На критичные технические проблемы (error rate > 1%, latency > порога).
- На бизнес-метрики (резкое падение конверсии).
- На внешние интеграции (партнёрский API недоступен).
- Каналы: Slack, Telegram, email, SMS для критичных.
- Документированный runbook для каждого алерта.
Прозрачность интеграций:
- Логирование всех внешних вызовов.
- Метрики латенси и error rate для каждого партнёра.
- Алерты на деградацию.
Health checks и uptime monitoring:
- Liveness и readiness probes для каждого сервиса.
- Внешний uptime-мониторинг (Better Uptime, Pingdom, российские аналоги).
Это уже:
- Резко снижает риски. Большинство инцидентов видно до того, как они стали критичными.
- Ускоряет разбор инцидентов. С минут до секунд.
- Повышает доверие бизнеса к системе. Руководитель видит, что система под контролем.
- Не требует космических бюджетов. Это 6–10 недель работы инженера для типового продукта.

11 · Что важно делать с данными
Собранные метрики и логи бесполезны, если с ними никто не работает. Несколько правил, которые отличают зрелую наблюдаемость от «дашборд есть, никто не смотрит».
Постоянно открытые дашборды. Команда видит ключевые метрики каждый день. Не «откроет если что» — а как часть рабочей среды.
Регулярная ретроспектива. Раз в неделю команда обсуждает: какие алерты сработали, какие проблемы видны на трендах, что нужно улучшить.
Каждый инцидент — post-mortem. После каждого крупного инцидента — короткий документ: что произошло, почему, как восстановили, что изменим. Это превращает инциденты в системные улучшения.
Алерты — конкретные, не «всё». Каждый алерт имеет смысл, владельца, инструкцию. Алерт без инструкции — это шум.
Метрики — для решений, не для красоты. Если дашборд никак не влияет на решения — он не нужен. Если влияет — нужно понять, какие именно решения.
Обновление наблюдаемости при изменениях. Новый сервис → новые метрики, новые алерты, новые дашборды. Это часть definition of done для любой задачи.
Доступ для всей команды. Не «только DevOps смотрит». Разработчик должен видеть метрики своего сервиса, продукт — конверсии и retention, поддержка — uptime.
12 · Чек-лист: 10 вопросов до настройки наблюдаемости
Прежде чем внедрять или улучшать систему мониторинга и логирования, ответьте на эти вопросы:
- Какие критичные сценарии в нашей системе? Что должно работать всегда.
- Как мы сейчас узнаём об инцидентах? От клиентов, от поддержки, из логов.
- Сколько времени занимает разбор типового инцидента?
- Какие метрики важны бизнесу? Не «CPU», а «успешные заказы», «конверсия», «время доставки».
- С какими внешними сервисами мы интегрируемся? Что мониторить.
- Какая инфраструктура? Облако, on-prem, контейнеры.
- Какой бюджет на инструменты наблюдаемости?
- Кто будет работать с данными? Кто настраивает, кто смотрит, кто реагирует.
- Какие требования к compliance? Логирование PII, retention, аудит.
- Что произойдёт через 12 месяцев, если ничего не менять?
Команда с внятными ответами обычно настраивает базовую наблюдаемость за 8–12 недель и видит измеримое улучшение в первый месяц. Команда без ответов — обычно покупает «универсальное решение», которое потом никто не использует.
Источники и что читать дальше
- CI/CD и DevOps для бизнеса: зачем это нужно, если «и так работает» — CI/CD как часть инфраструктурной гигиены.
- High-load системы в России: как готовиться к нагрузке до того, как она случилась — подготовка к нагрузке через наблюдаемость.
- Микросервисная архитектура: когда она нужна, а когда только вредит — почему микросервисы требуют distributed tracing.
- Enterprise-архитектура для стартапов: что действительно нужно, а что — лишнее — наблюдаемость как часть enterprise-подхода.
- Корпоративный MVP в 2026 году: почему «быстро и дёшево» больше не работает — что закладывать в MVP с самого начала.
- Как запустить MVP, который выдержит рост ×10 — без переписывания архитектуры — наблюдаемость как фундамент масштабирования.
- ФЗ-152 для SaaS-продуктов в 2026: что реально требует архитектура (а не только бумажки) — аудит-лог как требование 152-ФЗ.
- devops infrastructure — наш подход к инфраструктуре и observability.
- backend development — backend, готовый к наблюдаемости.
- custom software — разработка с встроенной наблюдаемостью.
Наблюдаемость — это не DevOps-мода и не техническая роскошь. Это основа управляемости IT-системы. Эта статья даёт фреймворк. Если у вас конкретная ситуация — мы делаем аудит мониторинга и логирования отдельно, до начала переделок.